

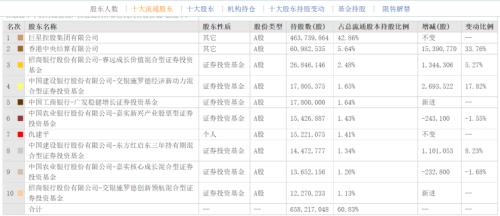
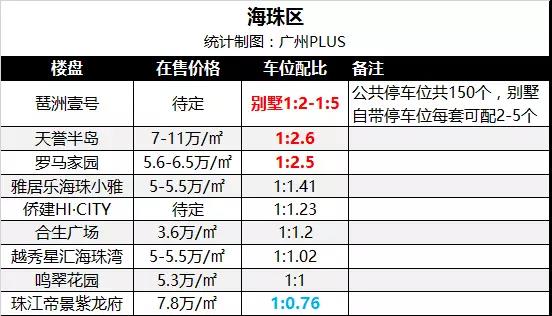
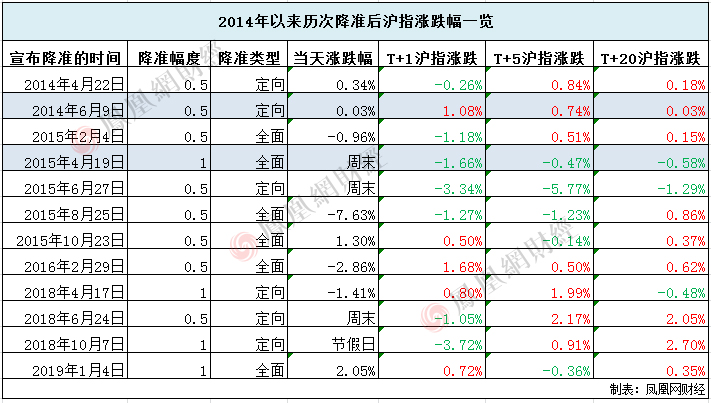
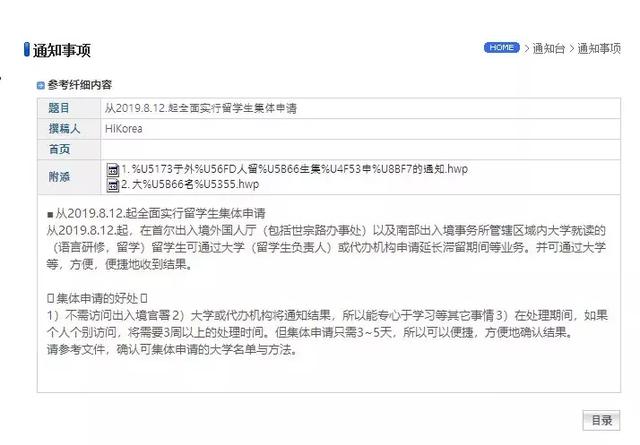
### 前言
在数字时代的浪潮中,数据分析和预测已经成为各行各业不可或缺的工具。无论是金融市场的波动预测,还是体育赛事的结果分析,准确的数据解读往往能带来巨大的优势。今天,我们将深入探讨一个备受关注的话题——“新澳门一码一码100准确”。这个概念不仅仅是一个简单的预测工具,它背后蕴含着复杂的数据分析和算法优化。对于初学者来说,掌握这一技能不仅能提升个人的数据分析能力,还能在实际应用中获得显著的成果。
本文将详细介绍如何通过一系列步骤,逐步掌握“新澳门一码一码100准确”的核心技术。无论你是数据分析的初学者,还是希望进一步提升技能的进阶用户,本文都将为你提供清晰、易懂的指导。我们将从基础的数据收集开始,逐步深入到复杂的算法应用和结果验证,确保你能够全面理解并掌握这一技能。
### 第一步:数据收集
在任何数据分析项目中,数据收集都是至关重要的第一步。对于“新澳门一码一码100准确”来说,我们需要收集与澳门相关的历史数据,包括但不限于彩票开奖结果、市场交易数据、以及相关的社会经济指标。这些数据将为我们后续的分析提供基础。
#### 1.1 确定数据来源
首先,我们需要确定可靠的数据来源。以下是一些常用的数据来源:
- **官方网站**:澳门彩票官方网站通常会提供详细的历史开奖数据,这是最直接和可靠的数据来源。
- **金融数据库**:如Bloomberg、Reuters等,可以提供与澳门市场相关的交易数据。
- **政府统计数据**:澳门特别行政区政府网站会发布各种社会经济指标,这些数据对于分析市场趋势非常有用。
#### 1.2 数据下载与整理
一旦确定了数据来源,接下来就是下载和整理数据。以下是具体步骤:
- **下载数据**:访问相关网站,下载所需的历史数据。通常,这些数据会以CSV、Excel或JSON格式提供。
- **数据清洗**:下载的数据可能包含缺失值、重复记录或格式不一致的问题。使用Excel或Python等工具进行数据清洗,确保数据的完整性和一致性。
**示例**:假设我们从澳门彩票官方网站下载了过去一年的开奖数据。数据格式如下:
| 日期 | 期号 | 开奖号码 |
|------------|------|----------|
| 2022-01-01 | 001 | 1, 2, 3 |
| 2022-01-02 | 002 | 4, 5, 6 |
| ... | ... | ... |
在Excel中,我们可以使用“筛选”功能去除重复记录,并使用“查找和替换”功能修正格式错误。
### 第二步:数据预处理
数据预处理是数据分析中的关键步骤,它直接影响后续分析的准确性。在这一步中,我们将对收集到的数据进行进一步的整理和转换,以便于后续的分析和建模。
#### 2.1 数据转换
在“新澳门一码一码100准确”的分析中,我们通常需要将原始数据转换为更适合分析的格式。例如,将开奖号码转换为数值型数据,或将日期转换为时间序列数据。
**示例**:假设我们有一个包含开奖号码的CSV文件,数据格式如下:
| 日期 | 期号 | 开奖号码 |
|------------|------|----------|
| 2022-01-01 | 001 | 1, 2, 3 |
| 2022-01-02 | 002 | 4, 5, 6 |
| ... | ... | ... |
我们可以使用Python的Pandas库将开奖号码转换为数值型数据:
```python
import pandas as pd
# 读取CSV文件
data = pd.read_csv('lottery_data.csv')
# 将开奖号码转换为数值型数据
data['开奖号码'] = data['开奖号码'].apply(lambda x: [int(num) for num in x.split(',')])
# 保存处理后的数据
data.to_csv('processed_lottery_data.csv', index=False)
```
#### 2.2 特征工程
特征工程是指从原始数据中提取有用的特征,以便于机器学习模型的训练。在“新澳门一码一码100准确”的分析中,我们可以提取一些与开奖号码相关的特征,如号码的和、平均值、标准差等。
**示例**:假设我们已经将开奖号码转换为数值型数据,接下来我们可以计算每个开奖号码的和、平均值和标准差:
```python
import numpy as np
# 计算开奖号码的和
data['号码和'] = data['开奖号码'].apply(lambda x: sum(x))
# 计算开奖号码的平均值
data['号码平均值'] = data['开奖号码'].apply(lambda x: np.mean(x))
# 计算开奖号码的标准差
data['号码标准差'] = data['开奖号码'].apply(lambda x: np.std(x))
# 保存处理后的数据
data.to_csv('feature_engineered_data.csv', index=False)
```
### 第三步:模型选择与训练
在数据预处理完成后,接下来就是选择合适的模型并进行训练。对于“新澳门一码一码100准确”的分析,我们可以选择多种机器学习模型,如线性回归、决策树、随机森林等。
#### 3.1 模型选择
选择合适的模型是关键步骤。不同的模型有不同的优缺点,适用于不同的数据类型和分析需求。以下是一些常用的模型:
- **线性回归**:适用于预测连续变量,如开奖号码的和。
- **决策树**:适用于分类和回归问题,能够处理非线性关系。
- **随机森林**:是决策树的集成模型,能够提高预测的准确性。
**示例**:假设我们选择随机森林模型来预测开奖号码的和。我们可以使用Python的Scikit-learn库来实现:
```python
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 读取处理后的数据
data = pd.read_csv('feature_engineered_data.csv')
# 定义特征和目标变量
X = data[['号码平均值', '号码标准差']]
y = data['号码和']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f'均方误差: {mse}')
```
#### 3.2 模型评估
模型训练完成后,我们需要对其进行评估,以确保其预测的准确性。常用的评估指标包括均方误差(MSE)、均方根误差(RMSE)和R平方(R²)。
**示例**:假设我们已经训练了一个随机森林模型,接下来我们可以计算其均方误差和R平方:
```python
from sklearn.metrics import r2_score
# 计算R平方
r2 = r2_score(y_test, y_pred)
print(f'R平方: {r2}')
```
### 第四步:结果验证与优化
在模型训练和评估完成后,我们需要对结果进行验证,并根据验证结果进行优化。这一步是确保“新澳门一码一码100准确”的关键。
#### 4.1 结果验证
结果验证是指将模型的预测结果与实际结果进行对比,以评估模型的准确性。我们可以使用交叉验证、留一法等方法来验证模型的稳定性。
**示例**:假设我们已经训练了一个随机森林模型,接下来我们可以使用交叉验证来验证其稳定性:
```python
from sklearn.model_selection import cross_val_score
# 使用交叉验证评估模型
scores = cross_val_score(model







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...